A common table design that you might be familiar with, is to have an identity column, could be int, or long, or uniqueidentifier, and then, a clustered index is conveniently created on that column. An identity is, technically speaking, the perfect choice for clustered index - it is not null, it is unique, and in most case it’s small. But is that really the best choice?
Maybe, maybe not.
Clustered index is critical to query performance, so they should be selected carefully. Your most frequent queries to that table should be taken into consideration - will it be able to utilize such index? Will you query your rows by the identity, or it is there, just because?
To demonstrate my point, today let’s go through a test with a table that was designed that way, and see what improvements we can make with a proper clustered index choice.
It’s a fairly simple table
CREATE TABLE [dbo].[ProductReview](
[Id] [uniqueidentifier] NOT NULL,
[Code] [nvarchar](150) NULL,
[ProductCode] [nvarchar](150) NULL,
[ReviewDate] [datetime] NOT NULL,
[ProductLink] [nvarchar](max) NULL,
[Rating] [int] NOT NULL,
[CustomerEmail] [nvarchar](255) NULL,
[CustomerName] [nvarchar](255) NULL,
[Country] [nvarchar](50) NULL,
[DateAdded] [datetime] NOT NULL,
[ReviewTitle] [nvarchar](255) NULL,
[HelpfulVotes] [int] NULL,
[DateCreated] [datetime] NULL,
[CreatedBy] [nvarchar](100) NULL,
[DateModified] [datetime] NULL,
[ModifiedBy] [nvarchar](100) NULL,
CONSTRAINT [PK_dbo.ProductReview] PRIMARY KEY CLUSTERED
(
[Id] ASC
)
I did some modifications to the table. Originally it has some
nvarchar(max)columns, which I think is a bad design choice. Unless if you are absolutely sure you need some very long values, it should generally be avoided. For starter you can’t add an index to anvarchar(max), and it opens the database to abuse
and here is the query
SELECT [p].[Id], [p].[Code], [p].[Country], [p].[CreatedBy], [p].[CustomerEmail], [p].[CustomerName], [p].[DateAdded], [p].[DateCreated], [p].[DateModified], [p].[Description], [p].[HelpfulVotes], [p].[ModifiedBy], [p].[ProductCode], [p].[ProductLink], [p].[Rating], [p].[ReviewDate], [p].[ReviewTitle]
FROM [ProductReview] AS [p]
WHERE [p].[Code] IN (
'abc123', 'xyz456'
)
ORDER BY [p].[ReviewDate] DESC
As expected, this will be a clustered index scan, and all rows will be scanned
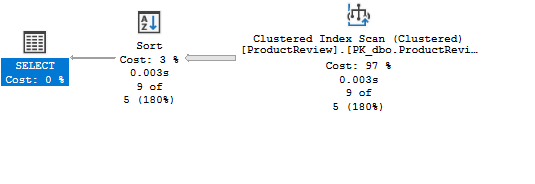
IO reads take a hit
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'ProductReview'. Scan count 1, logical reads 1055, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
It does not take a lot of experience to know that you need an index on Code, because you are querying by that column, so let’s do that. The performance improves quite drastically
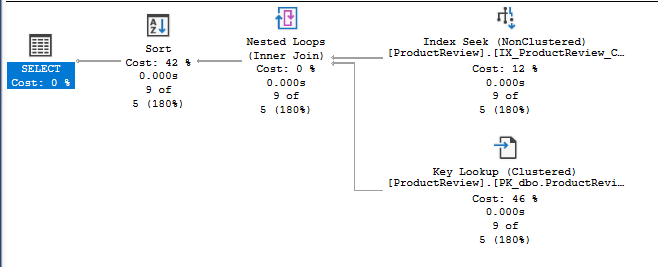
(9 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'ProductReview'. Scan count 2, logical reads 31, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
It was an easy, quick, and significant improvement, and in many cases, you can stop there. But can we do better?
As we can see from the execution plan, there was a Key Lookup. The reason was because while we can identify the rows using Code now, SQL Server still needs to retrieve other data (the columns in SELECT statement), and it has to do a key lookup to read those information. Key lookup is usually overlooked, but it can be a significant waste of IO reads. To get rid of key lookup, there are a few approaches
- To include the columns in the indexes. Sometimes this makes sense if we only need to include one or two columns, but because we are selecting many columns, that will make less senses.
- To make those columns part of the indexes. This makes even less senses than the previous approach. A index should only contain columns that are used for matching conditions.
- To make the index clustered.
For (3), because clustered index is how the table is structured, once you locate the row, you can read everything from it. This is not always viable - not an index is technically allowed to be clustered. But if it is, you need to make sure it is actually serving the most common query, or queries, on that table.
In this case, yes, and yes. It’s a bit tricky to drop the constraint on the identity key and make it unique non clustered (nothing CoPilot can’t help you with), but then creating a clustered index on Code is straightforward.
And voila!
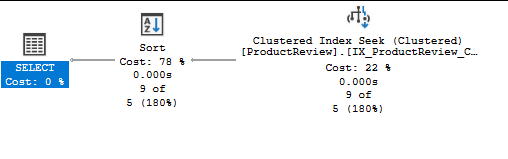
(9 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'ProductReview'. Scan count 2, logical reads 10, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
We reduced logical reads to 10. While 21 logical reads do not sound like a lot, it can add up very quickly for a frequently called query.
Moral of story? Think twice before selecting your clustered index. It does not have to be your identity columns. Picking the right clustered index could make a night and day difference to your query!
P/S you can see that
ReviewDateis used inORDER BYclause. If you include that in your index (which makes a perfect sense in this case asDateTimeis, most of the times, excellent choice for index), you can drop the logical reads a little bit more. But that’s more for fun than just practicality.