As string is the most common data type in an application, nvarchar and its variant varchar are probably the most common column types in your database. (We almost always use nvarchar because nchar is meant for fixed length columns which we don’t have). The difference is that nvarchar has encoding of UTF-16/USC-2 while varchar has UTF-8.
Starting with SQL Server 2012 (11.x), when a Supplementary Character (SC) enabled collation is used, these data types store the full range of Unicode character data and use the UTF-16 character encoding. If a non-SC collation is specified, then these data types store only the subset of character data supported by the UCS-2 character encoding.
But varchar can be harmful in a way that you don’t expect it to. Let’s assume we have this simple table with two columns (forgive naming, I can’t come up with better names):
CREATE TABLE [dbo].[Demo](
[varcharColumn] [varchar](50) NULL,
[nvarcharColumn] [nvarchar](50) NULL
)
Each will be inserted with same random values, almost unique. We will add a non clustered index on each of these columns, and as we know, the index should be very efficient on querying based on those values.
Let’s try with our varchar column first. It should work pretty well, right? Nope!
SELECT *
FROM dbo.[Demo]
where varcharColumn = N'0002T9'
Instead of a highly efficient Index seek, it does an Index scan on the entire table. This is of course not what you want.
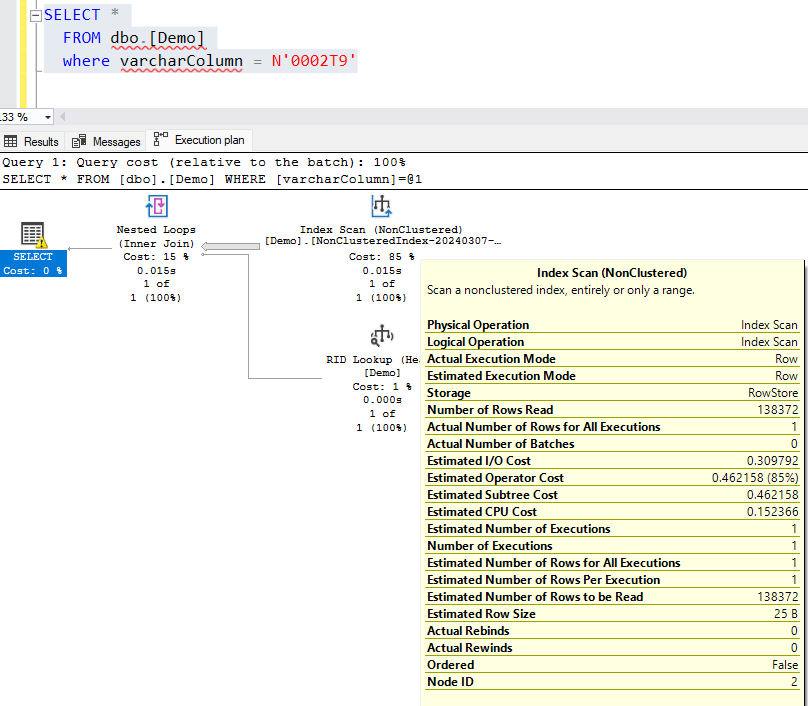
But, why?
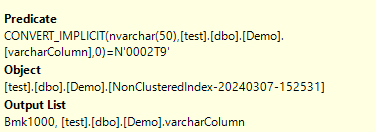
Good question. You might have noticed that I used N'0002T9' which is an nvarchar type – which is what .NET would pass to your query if your parameter is of type string. If you look closer to the execution plan, you’ll see that SQL Server has to do a CONVERT_IMPLICIT on each row of this column, effectively invalidating the index.
If we pass '0002T9' without the N notion though, it works as it should. This can cause confusion as it works during development, but once deployed it is much slower.
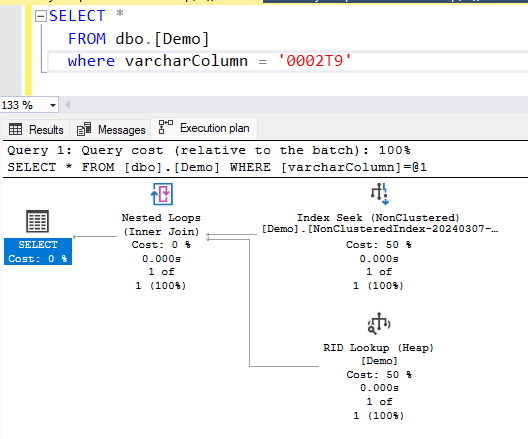
To see the difference we can run the queries side by side. Note that this is for a very simple table with 130k rows. If you have a few millions or more rows, the difference will be even bigger.
Query 1 (varchar parameter, Index Seek):
(1 row affected)
Table 'Demo'. Scan count 1, logical reads 4, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Query 2 (nvarchar parameter, Index Scan/Implicit Conversion):
(1 row affected)
Table 'Demo'. Scan count 1, logical reads 422, physical reads 0, page server reads 0, read-ahead reads 14, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
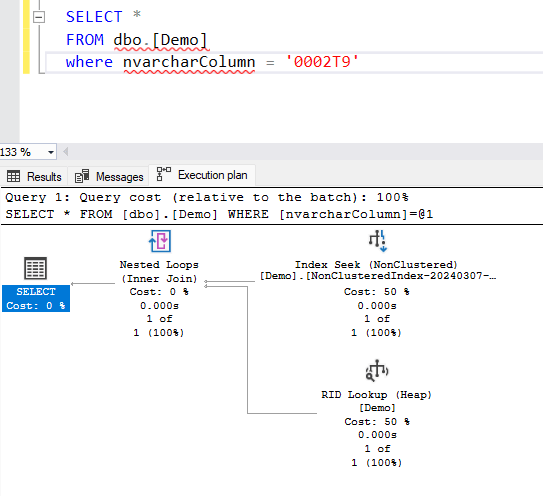
What about the vice versa?
If we have data as nvarchar(100) but the parameter is passed as varchar? SQL Server can handle it with ease. It simply converts the parameters to nvarchar and does an index seek, as it should.
Conclusion
So moral of the story? Unless you have strong reasons to use varchar (or char), stick with nvarchar (or nchar) to avoid complications with data type conversion which can, and will hurt your database performance.